垃圾收集算法一览
本文共 902 字,大约阅读时间需要 3 分钟。
根搜索收集器
跟踪收集器采用的为集中式的管理方式,全局记录对象之间的引用状态,执行时从一些列GC Roots的对象做为起点,从这些节点向下开始进行搜索所有的引用链,当一个对象到GC Roots 没有任何引用链时,则证明此对象是不可用的。
下图中,对象Object6、Object7、Object8虽然互相引用,但他们的GC Roots是不可到达的,所以它们将会被判定为是可回收的对象。
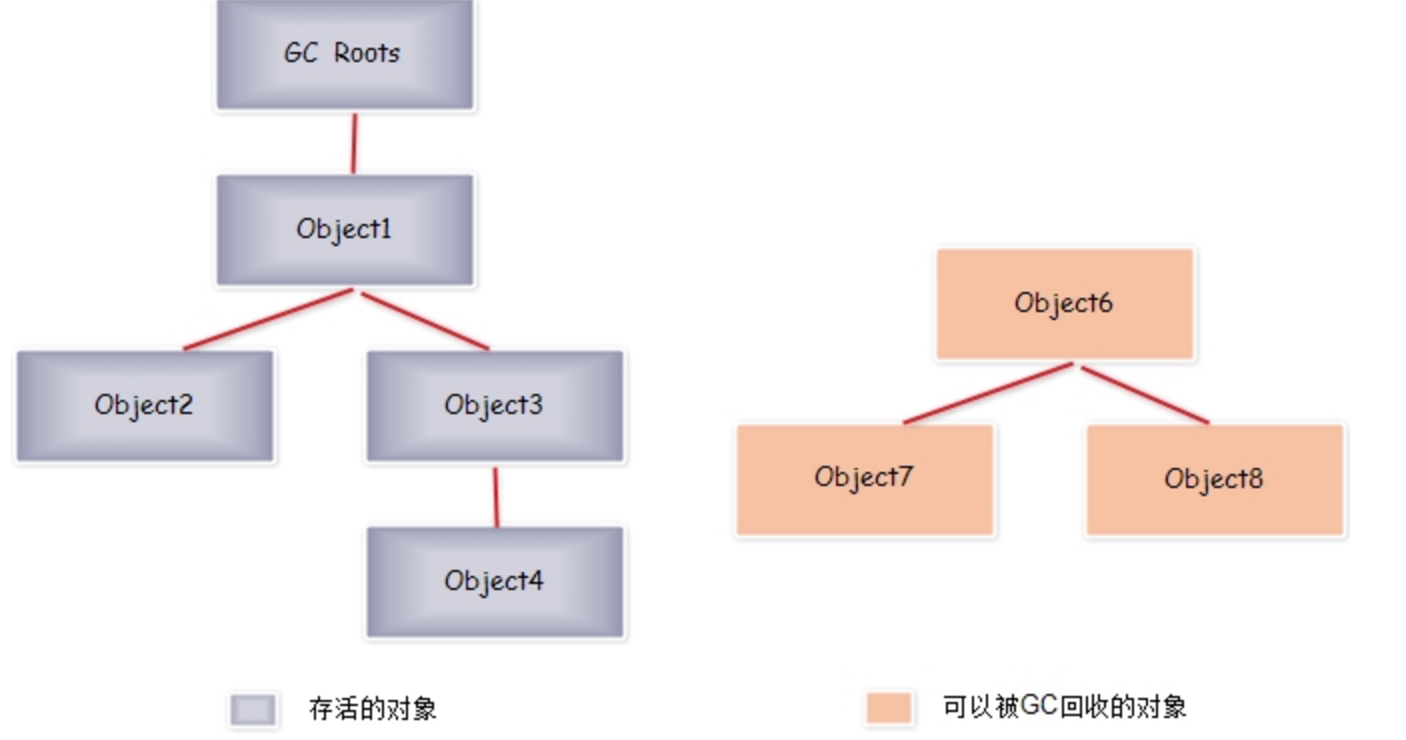
可作为GC Roots 的对象包括:
- 虚拟机栈(栈帧中的本地变量表)中的引用对象。
- 方法区中的类静态属性引用的对象
- 方法区中的常量引用的对象
- 本地方法栈中JNI的引用对象。
主要有复制、标记清除、标记压缩三种实现算法。
标记 - 清除算法
标记清除算法是最基础的收集算法,其他收集算法都是基于这种思想。标记清除算法分为“标记”和“清除”两个阶段:首先标记出需要回收的对象,标记完成之后统一清除对象。
它的主要缺点:- 标记和清除过程效率不高
- 标记清除之后会产生大量不连续的内存碎片。
复制算法
它将可用内存容量划分为大小相等的两块,每次只使用其中的一块。当这一块用完之后,就将还存活的对象复制到另外一块上面,然后在把已使用过的内存空间一次清理掉。这样使得每次都是对其中的一块进行内存回收,不会产生碎片等情况,只要移动堆订的指针,按顺序分配内存即可,实现简单,运行高效。
主要缺点:- 内存缩小为原来的一半。
标记 - 整理算法
标记操作和“标记-清除”算法一致,后续操作不只是直接清理对象,而是在清理无用对象完成后让所有存活的对象都向一端移动,并更新引用其对象的指针。
主要缺点:- 在标记-清除的基础上还需进行对象的移动,成本相对较高,好处则是不会产生内存碎片。
引用计数收集器
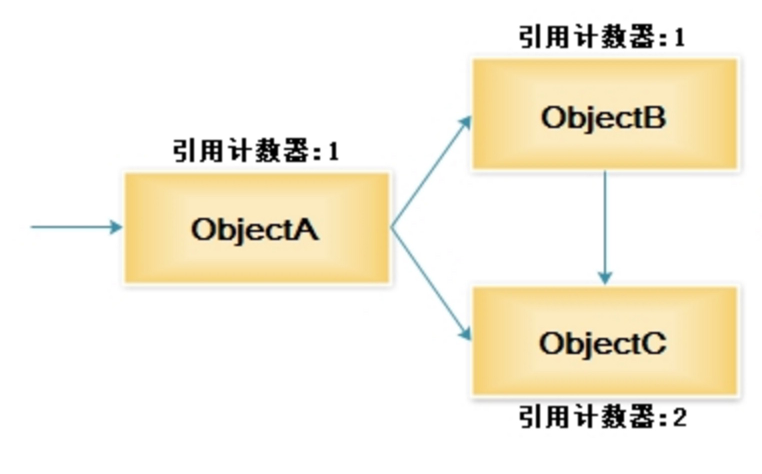
引用计数收集器采用的是分散式管理方式,通过计数器记录对象是否被引用。当计数器为0时说明此对象不在被使用,可以被回收。
主要缺点:- 循环引用的场景下无法实现回收,例如下面的图中,ObjectC和ObjectB相互引用,那么ObjectA即便释放了对ObjectC、ObjectB的引用,也无法回收B,C。sunJDK在实现GC时未采用这种方式。
转载地址:http://eduoo.baihongyu.com/
你可能感兴趣的文章
Android onclicklistener中使用外部类变量时为什么需要final修饰【转】
查看>>
《Spring2之站立会议9》
查看>>
0059-乘积问题
查看>>
2019年的第一篇随笔
查看>>
关于公网ip的一些信息(摘抄)
查看>>
5分钟弄懂Docker!
查看>>
BZOJ1076:[SCOI2008]奖励关(状压DP,期望)
查看>>
BZOJ2223/3524:[POI2014] Couriers(主席树)
查看>>
MyEclipse — Maven+Spring+Struts+Hibernate 整合 [学习笔记-5]
查看>>
Nodejs 连接各种数据库集合例子
查看>>
easyui的datagrid用js插入数据等编辑功能的实现
查看>>
Windows App开发之集合控件与数据绑定
查看>>
AMD、CMD/AMD与CMD的区别
查看>>
Python~第一天
查看>>
Linux管理用户账号
查看>>
redis中使用lua脚本
查看>>
颜色数组
查看>>
ELASTICSEARCH清理过期数据
查看>>
oo第三次博客作业
查看>>
人工智能简介
查看>>